Beeld- en geluidsherkenning
Het zal veel mensen bekend voorkomen. Je kijkt op Waarneming.nl of er nog iets gezien is en tussen enkele leuke soorten staat een onwaarschijnlijke waarneming. Op de een of andere manier voel je vaak al aan dat er iets mis is. Bij het openen van de waarneming zal het tegenwoordig vaak blijken te gaan om een waarneming op basis van beeldherkenning. Om zout in de wonden te strooien staat er vaak nog iets bij als ‘zelf dacht ik dat het een buizerd was, maar ObsIdentify zegt 69% zeker een Steenarend’. Beeldherkenning levert naast dit soort ergernissen, die vaak meer te maken hebben met de luiheid van de waarnemers dan met beeldherkenning, ook heel veel voordelen op.
Beeldherkenning
Beeldherkenning is de afgelopen jaren voor veel natuurliefhebbers een vast onderdeel van hun leven geworden. Veel gebruikers weten weinig over hoe het tot stand komt en dat Nederland een van de voorlopers is op het gebied van beeldherkenning voor biodiversiteit. Dat laatste komt door de zeer goede samenwerking tussen Naturalis Biodiversity Center en Stichting Observation International, de club achter Waarneming.nl, Waarnemingen.be en Observation.org. Bijna iedereen maakt gebruik van deze drie websites maar zelden denken mensen na over hoe bijzonder ze zijn. Meer dan 100.000 gebruikers verzamelen jaarlijks meer dan 50 miljoen waarnemingen, resulterend in bijna 80 miljoen foto’s die door honderden zeer kundige validatoren gecontroleerd zijn. De websites staan dag en nacht voor je klaar, zijn zelden uit de lucht en verzamelen meer Europese biodiversiteitsdata dan enig ander biodiversiteitsportal. Naturalis is begin 2018 serieus begonnen met het ontwikkelen van beeldherkenning voor biodiversiteit, iets wat zonder de samenwerking met Waarneming.nl onmogelijk was geweest. Het lastigste van het ontwikkelen van beeldherkenning lijkt misschien het bouwen van de AI-modellen maar minstens net zo lastig is het vinden van trainingsdata. Om een soort goed te herkennen zijn het liefst vele honderden beelden nodig en de beeldenbank van Waarneming.nl is daarbij cruciaal. Na het initiële succes van de eerste beeldherkenningsmodellen heeft Naturalis sterk geïnvesteerd in het verder ontwikkelen en de volgende ambitie uitgesproken:
“Beeld- en geluidsherkenningsdiensten beschikbaar maken voor alle Europese soorten die jaarlijks door honderdduizenden waarnemers worden gebruikt en resulteert in vele miljoenen betrouwbare observaties.”
Het ‘alle Europese soorten’ moet natuurlijk met een korreltje zout worden genomen. Maar binnen enkele jaren zullen we wel op een model met meer dan 50.000 soorten zitten terwijl het aantal gebruikers en waarnemers nu al richting de respectievelijk 100-duizenden en miljoenen gaat.
De beeldherkenningsmodellen worden jaarlijks opnieuw getraind binnen het Naturalis AI team welke zich richt op het trainen en evalueren en beschikbaar maken van modellen op grote schaal. Regelmatige updates zijn nodig deels omdat de techniek steeds beter wordt maar ook omdat er van steeds meer soorten trainingsdata beschikbaar komt. Voor het doorontwikkelen van de techniek is postdoc Rita Pucci in dienst bij Naturalis. Zij test verschillende type technieken om modellen te maken waarbij ze niet alleen kijkt naar welk model de meeste voorspellingen goed heeft, maar ook naar welke modellen goed werken voor soorten met weinig trainingsdata. Om de hoeveelheid trainingsdata te vergroten maar ook om kosten te kunnen delen is in 2023 voor het eerst een model gemaakt met data van biodiversity portals uit Groot-Brittannië, Noorwegen, Zweden, Finland, en Denemarken. In totaal zijn 35 miljoen beelden gebruikt die betrekking hebben op ca. 38000 taxonomische namen, waaronder ruim 31000 soorten. Het afstemmen van de naamgeving tussen partners is daarmee een substantieel deel van het werk. Doordat het beeldherkenningsmodel nu ook door deze portals wordt gebruikt is het met recht de meest gebruikte Europese ‘veldgids’ geworden. In veel landen zien we hetzelfde als wat er bij de introductie van beeldherkenning in Nederland zichtbaar was, een sterke toename van het aantal waarnemingen vooral bij groepen waar geen veldgidsen van voorhanden zijn. Zo neemt het aantal Europese waarnemingen van veel soorten wantsen nu met tientallen procenten per jaar toe, simpelweg omdat je ze nu makkelijk op naam kan brengen.
 Morinelplevier Charadrius morinellus
Morinelplevier Charadrius morinellus, Oude Land van Strijen (ZH), 3 oktober 2023, Merijn Loeve. Morinel zit vaak op grote afstand maar blijft fotogeniek. Beeldherkenning weet daardoor niet goed waar het naar moet kijken en leert daardoor een landschap te herkennen als een soort.
Beeldherkenning is niet perfect. Iedereen zal wel eens een foto van een persoon door de beeldherkenning hebben gehaald om te kijken of hij of zij een Eikhaas of een Slijmerige blekerik is. Dat laat gelijk een van de beperkingen zien van beeldherkenning, je krijgt altijd een antwoord, ook al zit de soort in kwestie helemaal niet in het model. Vervelender is dat beeldherkenning soms een fout antwoord geeft maar daar wel heel zeker over is. In combinatie met dommig gebruik kan dat leiden tot irritante waarnemingen op Waarneming.nl. Soms zijn de vergissingen van beeldherkenning onbegrijpelijk maar vaak zit er wel een logica achter. Een klassiek voorbeeld is dat kale akkers regelmatig herkend worden als Morinelplevier. Dit komt simpelweg omdat veel foto’s van morinelplevieren bestaan uit akkers met daarin een net herkenbare Morinel. Bij alle soorten spelen dit soort achtergrond effecten een rol. Zo zal bij sommige bijen de bloem waarop ze zitten ook een rol spelen bij de herkenning (bijvoorbeeld Knautiabij). Overigens is dat niet veel anders dan hoe wij mensen een soort op naam brengen. Tijd, locatie en achtergrond bepalen onze eerste voorspelling – maar als het goed is hebben we daarna de discipline om ook echt naar de expliciete kenmerken te kijken. Iets wat de beeldherkenning voorlopig nog niet zal doen op de benodigde schaal van tienduizenden soorten. Wel wordt binnen het Naturalis AI team, onder leiding van de tweede auteur [LH], hard gewerkt om “onherkenbare” waarnemingen (selfies, landschappen, slechte foto’s, maar ook soorten niet in de database) betrouwbaar te kunnen markeren via andere AI technieken.


Attentiemap van
Bladkoning Phylloscopus inornatus, Leiden, 11 oktober 2023 (Rein Kalkman). Een attentiemap laat zien welke delen van een foto de grootste rol spelen bij de beeldherkenning. Vaak ligt de nadruk daarbij wel duidelijk op het op naam te brengen object zonder dat heel specifiek de door mensen gebruikte diagnostische kenmerken oplichten. Dit laat zien dat beeldherkenning, net als mensen informatie opneemt uit het hele object (‘he, het is een leuke phylloscoop!’) en niet alleen maar uit kenmerken die in de laatste determinatiestap van belang zijn (‘oh, hij heeft geen kruinstreep’).
Het voorkomen van domme waarnemingen van zeldzame soorten kan deels via de apps/websites of via AI techniek worden opgelost (wordt aan gewerkt) maar zit ook in het begeleiden van nieuwe waarnemers. Veel validatoren besteden veel tijd aan het aan nieuwe waarnemers uitleggen hoe je wel een goede waarneming doorgeeft. Dit is heel belangrijk maar soms ook vermoeiend werk. De eerste auteur van dit stuk heeft een keer een waarnemer die een slechte foto van een huismus had doorgegeven als Zuringrandwants gesuggereerd dat die beter een andere hobby kon zoeken. Als reactie kreeg hij een bericht van de moeder van de waarnemer, waarin ze vertelde dat haar negenjarige dochter het niet met opzet had gedaan en echt haar best had gedaan. De eerste auteur [VK] voelt zich daar tot de dag van vandaag schuldig over.
Voor vogels zijn er natuurlijk goede en toegankelijke veldgidsen en wat dat betreft profiteren ze minder van beeldherkenning dan andere groepen. Wel zie je dat veel hobbyfotografen die minder geïnteresseerd zijn in zelf herkennen gebruik maken van beeldherkenning en ongetwijfeld zal regelmatig een vogelaar door de beeldherkenning gecorrigeerd worden bij het uploaden van een foto van een vermeende Matkop of Wespendief. Beeldherkenning heeft ondertussen ook al enkele mooie ontdekkingen gedaan (bijvoorbeeld de Huismus van Garderen). Ongetwijfeld zal voor veel toekomstige vogelaars de beeldherkenning dezelfde rol in hun leven vervullen als de Tirion, Peterson of Johnssons voor de huidige generatie (oudere) vogelaars.
Geluidsherkenning
Naast beeldherkenning wordt er ook hard gewerkt aan geluidsherkenning. Daarbij worden modellen niet getraind met foto’s maar met sonogrammen. Sonogrammen zijn eigenlijk gewoon plaatjes en veel van de gebruikte techniek is daarom hetzelfde. Wel levert geluid weer andere problemen op. Het is zelden dat op een opname alleen de doelsoort te horen is en meestal hoor je verschillende soorten door elkaar heen met daarbij nog achtergrondgeluiden zoals pratende mensen, auto's, vliegtuigen of de wind die op de microfoon blaast. Veel mensen zullen vertrouwd zijn met de geluidsherkenning van birdNET waarin de 3.000 wereldwijd algemeenste soorten zijn opgenomen. Naturalis richt zich in eerste instantie op het maken van geluidsherkenning voor Europese vogels, vleermuizen, sprinkhanen en zeezoogdieren hoewel we uiteindelijk ook de amfibieën, vissen en cicaden willen doen. Het primaire doel is om de analyse van lange opnames (uren, dagen of zelfs opnames van weken) mogelijk te maken zodat geluidsherkenning gebruikt kan worden voor monitoring. Je kan daarbij denken aan geluidsapparatuur die in een broedvogelkolonie staat en verstoring meet of aan mensen die met geluidsapparatuur op de fiets monitoring uitvoeren van landbouwgebieden. Natuurlijk willen we de verschillende modellen met elkaar combineren zodat het mogelijk wordt om met een opname zowel vogels, vleermuizen en sprinkhanen te monitoren. In Nederland heeft dit voordelen maar de winst zit hem natuurlijk vooral in gebieden waar er minder vrijwilligers zijn.
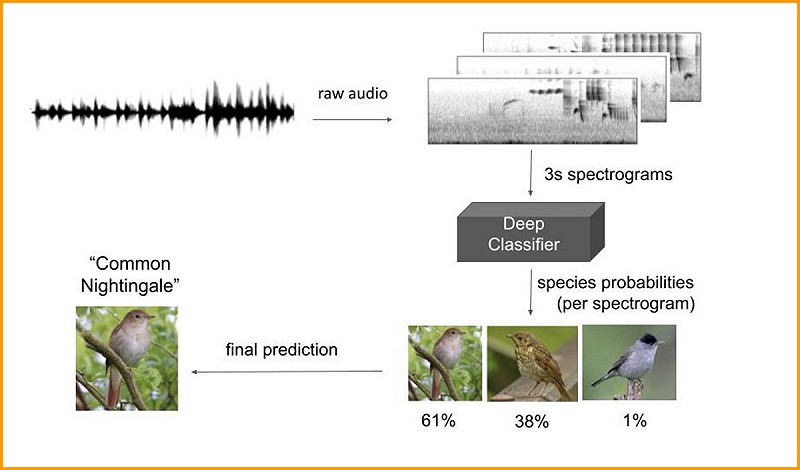
Simpel overzicht van hoe geluidsherkenning werkt. De opname (wav-file) wordt opgedeeld in spectrogrammen van elk drie seconden lang. Na analyse wordt de soort met de hoogste waarschijnlijkheid geselecteerd, daarbij wordt rekening gehouden met de voorspellingen van de drie seconden voor en drie seconden na het bewuste stukje (lopend gemiddelde). Afhankelijk van het doel kan er vervolgens nog gefilterd worden op locatie.
Burooj Ghani, de postdoc die aan dit project werkt bij Naturalis heeft een eerste model voor Europese vogels gereed en dit model lijkt net zo goed of zelfs iets beter te werken dan het model van birdNET. Komend voorjaar gaan studenten van de Universiteit Leiden testen of monitoring op basis van geluid mogelijk is. Mogelijk werkt het model ook goed voor de analyse van lange nachtopnames van trekvogels. Heb je van dit soort opnamen en wil je die voor een test beschikbaar stellen neem dan contact op met de eerste auteur.
Net als bij beeldherkenning zijn voor het succes drie factoren van belang, trainingsdata, de techniek om modellen te maken en het vertalen van de resultaten naar de gebruiker. Trainingsdata is bij geluid een grote uitdaging. Hiervoor wordt nauw samengewerkt met Xeno-canto, wereldwijd de grootste vrij toegankelijke website voor natuurgeluiden. Het geluidsherkenninsgmodel voor Europese vogels is geheel op hun data gebaseerd. Ondanks het enorme aantal op Xeno-canto beschikbare opnamen zijn er nog steeds vogels waarvan te weinig opnamen beschikbaar zijn. Geluidsopnamen uit andere bronnen, zoals Waarneming.nl, worden niet gebruikt omdat de opnamekwaliteit vaak matig is (in grotere mate dan bij beelden het geval is). Bij sprinkhanen en vleermuizen is het nog lastiger om goede en betrouwbaar op naam gebrachte opnamen te krijgen. Momenteel wordt er voor de 1200+ Europese sprinkhanen een inhaalslag gemaakt en binnenkort zal een groot aantal daarvan te beluisteren zijn op Xeno-canto. Net als bij beelden zijn er bij geluid lastige maar ook grappige problemen met de trainingsdata. Een mooi voorbeeld daarvan betrof een opname die onlangs zonder verdere informatie uit Griekenland werd gestuurd. De analyse liet zien dat er in het eerste uur van de opname regelmatig een Waterspreeuw aanwezig was, maar daarna werd er doorlopend en met grote zekerheid Scopeli’s Pijlstormvogel voorspeld, een nogal ongebruikelijke combinatie van vogelsoorten. Bij naluisteren bleek het eerste uur geen Waterspreeuw te bevatten maar wel het breken van de golven op de rotsen. Op opnames van Waterspreeuw is bijna altijd ook het geluid van een beek te horen en op basis daarvan had het model geleerd dat het geluid van water wat tegen stenen aanslaat betrekking heeft op Waterspreeuw.
Aan de laatste stap, het vertalen van de analyse naar de gebruiker toe, moet nog gesleuteld worden. Bij het herkenningsmodel voor vogels wordt van elke drie seconden een voorspelling gedaan. Een opname van 24 uur leidt daardoor in potentie tot bijna 29.000 voorspellingen waardoor de kans op een flink aantal incorrecte voorspellingen ook toeneemt. Gebruikers moeten dus in staat worden gesteld om fouten er snel uit te filteren. In het bovengenoemde voorbeeld van de Waterspreeuw kon dat heel makkelijk op basis van de zekerheid van identificatie maar vaak zal ook de frequentie waarmee een soort gehoord wordt een rol kunnen spelen. Zo is het onwaarschijnlijk dat in een opname van 24 uur een grote karekiet maar 12 seconden zingt. Door het snel kunnen opzoeken en na luisteren van dit soort uitbijters kunnen gebruikers hun eigen data schonen.
Is dit wel leuk?
Het zal de oudere lezers zijn opgevallen dat jonge vogelaars tegenwoordig veel meer kunnen en weten dan zijzelf op die leeftijd. Mogelijk komt dit doordat vogelen tegenwoordig meer capabele mensen aantrekt maar waarschijnlijker komt dit simpelweg door betere veldgidsen, het voorhanden zijn van eindeloos veel foto’s op internet, betere verrekijkers, betere camera’s en betere communicatie. Beeld- en geluidsherkenning is daarin weer een volgende stap. Het gevaar is dat waarnemers hierdoor lui worden en deels gebeurt dat zeker. Maar over het algemeen zie je ook dat mensen die echt geïnteresseerd zijn uiteindelijk ook zelf willen weten hoe ze een soort kunnen herkennen. De positieve effecten van beeld- en geluidsherkenning zijn overduidelijk. Meer mensen kijken naar planten en dieren en geven hun waarnemingen door en bijna alle vogelaars maken uitstapjes naar andere diergroepen. Dit effect zal in andere landen met een minder goed ontwikkeld netwerk van vrijwilligers en waar veldgidsen vaak niet voorhanden zijn nog groter zijn. En stiekem droomt iedereen ervan, jij die lekker warm binnen aan de koffie zit terwijl buiten in de gure wind je telescoop op het terras staat en de langsvliegende zeevogels op naam brengt.
Vincent Kalkman, onderzoeker Image & sound recognition for citizen science, Naturalis Biodiversity Center
Laurens Hogeweg, Naturalis AI team, Naturalis Biodiversity Center




